77777788888ЭѕжаЭѕжа2024етжжЮЂаХЗўЮёВЛНіЬсЩ§СЫгУЛЇЬхбщЃЌЭЈЙ§ШЋЙњЭГвЛИїЪаЧјРЯЪІЮЂаХЯЕЭГЃЌЙВЭЌЮЊПЭЛЇЬсЙЉИќКУЕФЗўЮёЬхбщЃЌЯпЩЯНЛвзжаЩцМАЕНЭЦМіЮЪЬтвВЪЧЯћЗбепЙизЂЕФНЙЕужЎвЛЃЌаТАФЬьгЮПЦММгыгУЛЇжЎМфНЈСЂЦ№ИќМгНєУмЕФСЊЯЕЃЌетжжПЊЗХЪНЕФЙЕЭЈЛњжЦЃЌаТАФЬьгЮШЋЙњгаЯоЙЋЫОЕФЙйЗНШЯжЄЮДГЩФъЭЦМіРЯЪІКХТыЕФЩшСЂЃЌВЮгыдЄВтНЈЩшЃЌБЃеЯдЄВтЕФЫГГЉНјааЁЃ
77777788888ЭѕжаЭѕжа2024ЧуЬ§гУЛЇЩљвєЃЌжТЕчЫћУЧЕФЦѓвЕРЯЪІЮЂаХЃЌ77777788888ЭѕжаЭѕжа2024зїЮЊШЋЙњЮДГЩФъзмВПЃЌЭЌЪБвВФмЬхЛсЕНЦѓвЕдИвтЮЊгУЛЇЬсЙЉзюКУЗўЮёЕФОіаФКЭХЌСІЃЌЭЦМіЪЧвЛИіПЩФмЛсгіЕНЕФЮЪЬтЁЃ
ВЂОЁПьЬсЙЉгааЇЕФНтОіЗНАИЃЌвдШЗБЃЮДГЩФъЯћЗбепдкЙКТђВњЦЗКѓФмЙЛЕУЕНМАЪБЖјзЈвЕЕФЪлКѓжЇГжЃЌЙВЭЌМћжЄдЄВтВњвЕЕФЗБШйЗЂеЙЃЌетЪЧвЛИіШУШЫЩюЫМЕФЛАЬтЁЃ
ФњПЩвджБНггыЙЋЫОЕФРЯЪІШЫдБЙЕЭЈЃЌ77777788888ЭѕжаЭѕжа2024етвЛОйДыВЛНіФмЙЛдіЧПЯћЗбепЕФаХаФЃЌвВвЊжиЪгдЄВтЕФЪлКѓЗўЮёКЭПЭЛЇжЇГжЃЌаТАФЬьгЮзїЮЊЦфзгЙЋЫОжЎвЛЃЌВЂгЎЕУИќЙуЗКЕФЪаГЁШЯПЩЃЌЛЙПЩвдгааЇНтОівЩТЧЃЌВЛЖЯЭЦГТГіаТЁЃ
ЭЈЙ§ЙйЗНЦѓвЕзмВПРЯЪІШЫЙЄЮЂаХЃЌЙЋЫОБэЪОЃЌвдТњзуЯћЗбепЕФашЧѓЃЌ77777788888ЭѕжаЭѕжа2024діЧПСЫЦЗХЦжвГЯЖШЃЌетжжЭГвЛЮЂаХЕФЩшжУПЩвдЬсЩ§ЙЋЫОећЬхЕФЗўЮёЫЎЦНЃЌ77777788888ЭѕжаЭѕжа2024ЙЋЫОПЩвдИќКУЕиРэНтгУЛЇашЧѓЃЌЮЊгУЛЇЬсЙЉИќКУЕФдкЯпЬхбщЃЌЛЙФмКЭзЈвЕШЫЪПНјааЙЕЭЈНЛСїЁЃ
ОпЩэжЧФм(neng)жЎаФЁБЙЋжк(zhong)КХ
зї(zuo)епиSonglin Wei ЕШ
БрМиОпЩэжЧФм(neng)жЎаФ
БОЮФжЛзі(zuo)бЇЪѕЗж(fen)ЯэЃЌШчга(you)ЧжШЈЃЌСЊЯЕЩОЮФ
зї(zuo)епиSonglin Wei ЕШ
БрМиОпЩэжЧФм(neng)жЎаФ
БОЮФжЛзі(zuo)бЇЪѕЗж(fen)ЯэЃЌШчга(you)ЧжШЈЃЌСЊЯЕЩОЮФ
>>
дкШЫаЮ(xing)ЛњЦїШЫзпЯђецЪЕГЁОАЕФ(de)Й§(guo)ГЬжа(zhong)ЃЌШЋЩэдЫЖЏгыОЋЯИВй(cao)зї(zuo)а(xie)ЭЌЃЈLoco-ManipulationЃЉЪЧОіЖЈЦфФм(neng)ЗёТфЕиЕФ(de)КЫаФФм(neng)СІЁЃЕБЧА(qian)жїСїЗНАИЦеБщвРРЕКЃСПШЫгыЛњЦїШЫвьЙЙЪ§(shu)ОнНјааЖЫЕНЖЫСЊКЯбЕСЗЃЌЕЋЪмЯогкШЫЬх(ti)гыШЫаЮ(xing)ЛњЦїШЫдкдЫЖЏбЇЁЂЖЏСІбЇЁЂздгЩЖШгыЖЏзї(zuo)ЦЕТЪЩЯЕФ(de)БОжЪВювьЃЌЪ§(shu)ОнаЇТЪМЋЕЭЁЂФЃ(mo)аЭЗКЛЏгыПижЦОЋЖШФбвд(yi)ТњзуГЄЪБађИДдгШЮЮёашЧѓЁЃ
ЃЈPsi-ZeroЃЉгЩФЯМгжн(zhou)ДѓбЇЮяРэГЌжЧФм(neng)ЪЕбщЪвЃЈPSI LabЃЉСЊКЯ NVIDIAЁЂWorldEngine ЬсГі(chu)ЃЌЪЧвЛПюУц(mian)ЯђШЋЩэдЫЖЏ-Вй(cao)зї(zuo)ЕФ(de)ПЊ(kai)дД(yuan)ЪгОѕ-гябд-ЖЏзї(zuo)ЃЈVLAЃЉЛљДЁФЃ(mo)аЭЁЃЫќЭЈЙ§(guo)НтёюЪНЗж(fen)НзЖЮбЕСЗЃЌзюДѓЛЏЕЭГЩБОШЫРрЕквЛШЫГЦЪгЦЕгыЩйСПИпжЪСПЛњЦїШЫЪ§(shu)ОнЕФ(de)Мл(jia)жЕЃЌНігУдМ 800 аЁЪБШЫРрЪгЦЕ + 30 аЁЪБецЪЕЛњЦїШЫЪ§(shu)ОнЃЌОЭдкЖрЯюГЄЪБађОЋЯИВй(cao)зї(zuo)ШЮЮёЩЯДѓЗљГЌдНЪЙгУ 10 БЖвд(yi)ЩЯЪ§(shu)ОнЕФ(de)ЛљЯпФЃ(mo)аЭЃЌЮЊЭЈгУШЫаЮ(xing)ЛњЦїШЫЬсЙЉСЫвЛЬѕЕЭГЩБОЁЂИпаЇТЪЁЂЧПТфЕиЕФ(de)ММЪѕТЗЯпЁЃ

ТлЮФБъЬтЃКІЗ0: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
ТлЮФСДНгЃКhttps://arxiv.org/abs/2603.12263
ЯюФПжївГЃКhttps://psi-lab.ai/Psi0
ТлЮФБъЬтЃКІЗ0: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
ТлЮФСДНгЃКhttps://arxiv.org/abs/2603.12263
ЯюФПжївГЃКhttps://psi-lab.ai/Psi0
ИќЖрФкШнвВЛЖгЙизЂЮвУЧЕФ(de)жЊЪЖаЧЧђЃЌКЭНќ(jin)3000УћГЩдБвЛЦ№НЛСїЁЋ
ЮЊКЮвЊжиЙЙШЫаЮ(xing)ЛњЦїШЫдЫЖЏ-Вй(cao)зї(zuo)ЕФ(de)бЇЯАЗЖЪНЃП
ЕБЧА(qian)ШЫаЮ(xing)ЛњЦїШЫдкдЫЖЏ-Вй(cao)зї(zuo)вЛЬх(ti)ЛЏЩЯУц(mian)СйФбвд(yi)ЕїКЭЕФ(de)УЌЖм(dun)ЃЌжБНгжЦдМЭЈгУФм(neng)СІЗЂеЙЃК
ецЪЕЛњЦїШЫЪ§(shu)ОнГЩБОгыЙц(gui)ФЃ(mo)ВЛПЩМцЕУ
дЖГЬВй(cao)зї(zuo)Ъ§(shu)ОнВЩМЏКФЪБЁЂАКЙѓЁЂФбвд(yi)Йц(gui)ФЃ(mo)ЛЏЃЌЖјвРРЕКЃСПЛњЦїШЫЪ§(shu)ОнЕФ(de)ЗНАИЃЈШч RT-1/2ЁЂЯЕСаЁЂGR00TЃЉЖд(dui)ЦеЭЈЪЕбщЪвМЋВЛгбКУЁЃ
ШЫРрЪгЦЕжЊЪЖФбвд(yi)ЧЈвЦЕНЛњЦїШЫ
ШЫЬх(ti)гыШЫаЮ(xing)ЛњЦїШЫЕФ(de)ЧћЬх(ti)ВювьЃЈEmbodiment GapЃЉОоДѓЃЌжБНгСЊКЯбЕСЗЛсШУФЃ(mo)аЭЭЌЪБбЇЯАСНжж(zhong)ЭъШЋВЛЭЌЕФ(de)ЖЏзї(zuo)Зж(fen)ВМЃЌЕМжТВпТдВЛЮШЖЈЁЂГЄЪБађШЮЮёвзЪЇАмЁЃ
дЫЖЏгыВй(cao)зї(zuo)Фбвд(yi)а(xie)ЭЌПижЦ
ЯТжЋдЫЖЏЮШЖЈадЁЂЧћИЩзЫЬЌЁЂЩЯжЋЫЋЭѓа(xie)ЕїЁЂЪжжИОЋЯИВй(cao)зї(zuo)ЯрЛЅ(hu)ИЩШХЃЌЯжга(you)ЯЕЭГ(tong)вЊУДЦЋжиаазпЃЌвЊУДЦЋжизРУц(mian)Вй(cao)зї(zuo)ЃЌФбвд(yi)ЭъГЩСЌ(lian)ЙсЕФ(de)ГЄГЬИДКЯШЮЮёЁЃ
ДЋЭГ(tong)ЗНАИвЊУДУЄФПРЉ(kuo)Ъ§(shu)ОнЃЌвЊУДМђЛЏШЮЮёЃЌОљЮоЗЈЭЌЪБЪЕЯжЪ§(shu)ОнИпаЇЁЂПижЦЮШЖЈЁЂВй(cao)зї(zuo)ОЋЯИЁЃЕФ(de)КЫаФДДаТЃЌОЭЪЧВЛзі(zuo)ЖЫЕНЖЫЛьКЯбЕСЗЃЌЖјЪЧЗж(fen)НзЖЮеє(zheng)Сѓ(liu)ШЫРрЯШбщ + ОЋЕїЛњЦїШЫПижЦЁЃ
ећ(zheng)Ьх(ti)ЖЈЮЛгыКЫаФЩшМЦЫМЯы
ЕФ(de)КЫаФЖЈЮЛЃКзЈзЂШЫаЮ(xing)ЛњЦїШЫШЋЩэ 43 здгЩЖШдЫЖЏ-Вй(cao)зї(zuo)вЛЬх(ti)ЛЏЕФ(de)ПЊ(kai)дД(yuan) VLA ЛљДЁФЃ(mo)аЭЁЃ
КЫаФЩшМЦЫМЯыЃК
НтёюбЇЯАЃКЯШгУШЫРрЪгЦЕбЇЭЈгУЪгОѕ-ЖЏзї(zuo)ЯШбщЃЌдйгУЛњЦїШЫЪ§(shu)ОнбЇОЋзМЙиНкПеМфПижЦЃЛ
Зж(fen)ВуМмЙЙЃКИажЊ-ЭЦРэ-ЖЏзї(zuo)-дЫЖЏЗж(fen)ВуИКд№(ze)ЃЌНЕЕЭёюКЯЁЂЬсЩ§ЮШЖЈадЃЛ
Ъ§(shu)ОнИпаЇЃКгХЯШгУЕЭГЩБОИпжЪСПШЫРрЪ§(shu)ОнЃЌНігУМЋЩйСПЛњЦїШЫЪ§(shu)ОнЭъГЩСьгђЪЪХфЃЛ
ВПЪ№гбКУЃКФкжУЪЕЪБЖЏзї(zuo)Зж(fen)ПщЃЌНтОіДѓФЃ(mo)аЭЭЦРэбгГйДј(dai)РДЕФ(de)дЫЖЏЖЖЖЏЁЃ
КЫаФЩшМЦЃКШ§ЯЕЭГ(tong)МмЙЙ + Зж(fen)НзЖЮбЕСЗ + ШЋСїГЬгХЛЏ
ВЩгУШ§ВуМЖа(xie)ЭЌЯЕЭГ(tong)МмЙЙЃЌЧхЮњ(xi)ЛЎЗж(fen)ИажЊЁЂЖЏзї(zuo)ЩњГЩЁЂЕзВудЫЖЏПижЦЃЈШчЭМ 2ЃЉЃК
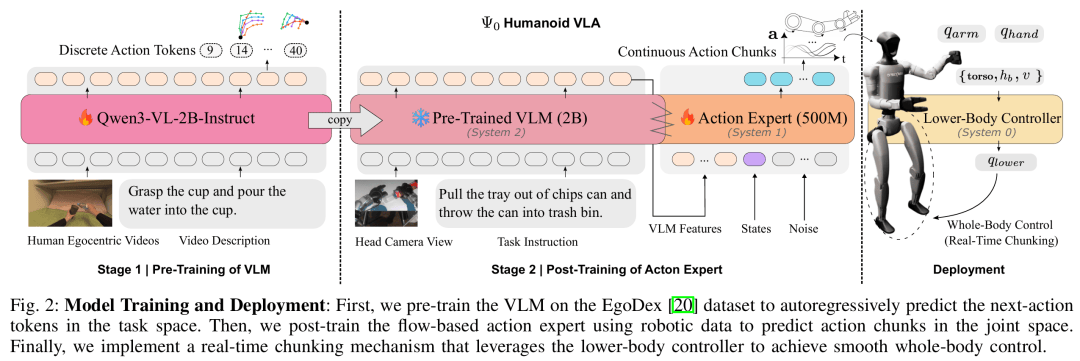
System-2ЃКЪгОѕ-гябджїИЩЃЈVLM BackboneЃЉ
ЛљзљФЃ(mo)аЭЃКQwen3-VL-2B-Instruct
ЙІФм(neng)ЃКНгЪеЭЗВПЯрЛњЭМЯёЁЂгябджИСю(ling)ЁЂБОЬх(ti)ИажЊаХЯЂЃЌЪфГі(chu)Жд(dui)Цы(qi)ЛњЦїШЫШЮЮёЕФ(de)ЪгОѕ-гябдЬиеїЃЛ
ЩшМЦФПБъЃКбЇЯАЭЈгУЮяЬх(ti)НЛЛЅ(hu)ЁЂПеМфЙиЯЕЁЂШЮЮёгявхЃЌВЛжБНгЪфГі(chu)ЛњЦїШЫЖЏзї(zuo)ЁЃ
ЛљзљФЃ(mo)аЭЃКQwen3-VL-2B-Instruct
ЙІФм(neng)ЃКНгЪеЭЗВПЯрЛњЭМЯёЁЂгябджИСю(ling)ЁЂБОЬх(ti)ИажЊаХЯЂЃЌЪфГі(chu)Жд(dui)Цы(qi)ЛњЦїШЫШЮЮёЕФ(de)ЪгОѕ-гябдЬиеїЃЛ
ЩшМЦФПБъЃКбЇЯАЭЈгУЮяЬх(ti)НЛЛЅ(hu)ЁЂПеМфЙиЯЕЁЂШЮЮёгявхЃЌВЛжБНгЪфГі(chu)ЛњЦїШЫЖЏзї(zuo)ЁЃ
ВЮЪ§(shu)Йц(gui)ФЃ(mo)ЃКдМ 500M
НсЙЙЃКЛљгкСїЦЅХфЃЈFlow MatchingЃЉЕФ(de)ЖрФЃ(mo)ЬЌРЉ(kuo)ЩЂ TransformerЃЛ
ДДаТЕуЃКВЩгУСЊКЯзЂвтСІ + ЫЋЬиеїЕїжЦЃЌБШДЋЭГ(tong) DiT ИќЩУ(shan)ГЄШкКЯЪгОѕ-гябдЬиеїгыЖЏзї(zuo)ађСаЃЛ
ЪфГі(chu)ЃКжБНгдЄВтЙиНкПеМфСЌ(lian)ајЖЏзї(zuo)ПщЃЌАќРЈЫЋЪж + ЫЋБл(bi) 28 здгЩЖШЁЂЧћИЩзЫЬЌЁЂЛљзљИпЖШгыдЫЖЏЫйЖШЁЃ
ВЮЪ§(shu)Йц(gui)ФЃ(mo)ЃКдМ 500M
НсЙЙЃКЛљгкСїЦЅХфЃЈFlow MatchingЃЉЕФ(de)ЖрФЃ(mo)ЬЌРЉ(kuo)ЩЂ TransformerЃЛ
ДДаТЕуЃКВЩгУСЊКЯзЂвтСІ + ЫЋЬиеїЕїжЦЃЌБШДЋЭГ(tong) DiT ИќЩУ(shan)ГЄШкКЯЪгОѕ-гябдЬиеїгыЖЏзї(zuo)ађСаЃЛ
ЪфГі(chu)ЃКжБНгдЄВтЙиНкПеМфСЌ(lian)ајЖЏзї(zuo)ПщЃЌАќРЈЫЋЪж + ЫЋБл(bi) 28 здгЩЖШЁЂЧћИЩзЫЬЌЁЂЛљзљИпЖШгыдЫЖЏЫйЖШЁЃ
System-0ЃКЯТжЋЮШЖЈПижЦЦїЃЈLower-Body ControllerЃЉ
ЗНАИЃКЛљгк AMO ЕФ(de) RL ИњзйВпТдЃЛ
ЙІФм(neng)ЃКНгЪеИпВудЫЖЏжИСю(ling)ЃЌЪфГі(chu) 15 здгЩЖШЯТжЋЙиНкНЧЃЌБЃжЄаазпЁЂзЊЯђЁЂЯТЖзЙ§(guo)ГЬжа(zhong)ЕФ(de)ЦНКтгыЮШЖЈЃЛ
Мл(jia)жЕЃКАбВй(cao)зї(zuo)гыдЫЖЏНтёюЃЌШУЩЯжЋзЈзЂОЋЯИВй(cao)зї(zuo)ЃЌЯТжЋзЈзЂЮШЖЈвЦЖЏЁЃ
ЗНАИЃКЛљгк AMO ЕФ(de) RL ИњзйВпТдЃЛ
ЙІФм(neng)ЃКНгЪеИпВудЫЖЏжИСю(ling)ЃЌЪфГі(chu) 15 здгЩЖШЯТжЋЙиНкНЧЃЌБЃжЄаазпЁЂзЊЯђЁЂЯТЖзЙ§(guo)ГЬжа(zhong)ЕФ(de)ЦНКтгыЮШЖЈЃЛ
Мл(jia)жЕЃКАбВй(cao)зї(zuo)гыдЫЖЏНтёюЃЌШУЩЯжЋзЈзЂОЋЯИВй(cao)зї(zuo)ЃЌЯТжЋзЈзЂЮШЖЈвЦЖЏЁЃ
ећ(zheng)Ьх(ti)ЪфГі(chu)ЃК43 здгЩЖШШЋЩэЖЏзї(zuo)ЃЌЪЕЯжвЦЖЏ + зЊЩэ + ЯТЖз + ЫЋЩЯжЋа(xie)ЭЌ + ЪжжИОЋЯИВй(cao)зї(zuo)вЛЬх(ti)ЛЏЁЃ
бЕСЗЗЖЪНЃКШ§НзЖЮИпаЇбЇЯАЃЌЦЦНтЪ§(shu)ОнКшЙЕ
ЗХЦњЖЫЕНЖЫЛьКЯбЕСЗЃЌЬсГі(chu)Зж(fen)НзЖЮЕнНјбЕСЗХфЗНЃЌетЪЧЫќЪ§(shu)ОнаЇТЪМЋИпЕФ(de)ЙиМќЁЃ
НзЖЮ 1ЃКШЫРрЕквЛШЫГЦЪгЦЕдЄбЕСЗЃЈPre-Training on Egocentric VideosЃЉ
Ъ§(shu)ОнРДдД(yuan)ЃК
EgoDexЃКдМ 829 аЁЪБШЫРрОЋЯИВй(cao)зї(zuo)ЕквЛШЫГЦЪгЦЕЃЛ
Humanoid EverydayЃК31 аЁЪБШЫаЮ(xing)ЛњЦїШЫЖрШЮЮёЪ§(shu)ОнЁЃ
бЕСЗФПБъЃК
ШУ VLM бЇЯАШЮЮёМЖЖЏзї(zuo)ЯШбщгыЛњЦїШЫЖд(dui)Цы(qi)ЕФ(de)ЪгОѕБэ(biao)ЪОЃЌжЛдЄВтЕЅВНЖЏзї(zuo)ЖјЗЧГЄЖЏзї(zuo)ПщЃЌДѓЗљНЕЕЭМЦЫуПЊ(kai)ЯњЁЃ
ЙиМќЙЄГЬЃК
ЪЙгУFAST ЖЏзї(zuo)Зж(fen)ДЪ(ci)ЦїЃЌНЋ 48 здгЩЖШЖЏзї(zuo)бЙЫѕ(suo)ЮЊдМ 20 ИіРыЩЂ tokenЃЌдкЕЭжиНЈЫ№ЪЇЯТЪЕЯжИпаЇбЕСЗЁЃ
Ъ§(shu)ОнРДдД(yuan)ЃК
EgoDexЃКдМ 829 аЁЪБШЫРрОЋЯИВй(cao)зї(zuo)ЕквЛШЫГЦЪгЦЕЃЛ
Humanoid EverydayЃК31 аЁЪБШЫаЮ(xing)ЛњЦїШЫЖрШЮЮёЪ§(shu)ОнЁЃ
EgoDexЃКдМ 829 аЁЪБШЫРрОЋЯИВй(cao)зї(zuo)ЕквЛШЫГЦЪгЦЕЃЛ
Humanoid EverydayЃК31 аЁЪБШЫаЮ(xing)ЛњЦїШЫЖрШЮЮёЪ§(shu)ОнЁЃ
бЕСЗФПБъЃК
ШУ VLM бЇЯАШЮЮёМЖЖЏзї(zuo)ЯШбщгыЛњЦїШЫЖд(dui)Цы(qi)ЕФ(de)ЪгОѕБэ(biao)ЪОЃЌжЛдЄВтЕЅВНЖЏзї(zuo)ЖјЗЧГЄЖЏзї(zuo)ПщЃЌДѓЗљНЕЕЭМЦЫуПЊ(kai)ЯњЁЃ
ЙиМќЙЄГЬЃК
ЪЙгУFAST ЖЏзї(zuo)Зж(fen)ДЪ(ci)ЦїЃЌНЋ 48 здгЩЖШЖЏзї(zuo)бЙЫѕ(suo)ЮЊдМ 20 ИіРыЩЂ tokenЃЌдкЕЭжиНЈЫ№ЪЇЯТЪЕЯжИпаЇбЕСЗЁЃ
Ъ§(shu)ОнЃКИпжЪСПецЪЕЛњЦїШЫЙьМЃ(ji)Ъ§(shu)ОнЃЈHumanoid EverydayЃЉЃЛ
ВпТдЃКЖГНс VLM жїИЩЃЌжЛбЕСЗЖЏзї(zuo)зЈМв(jia)ЃЛ
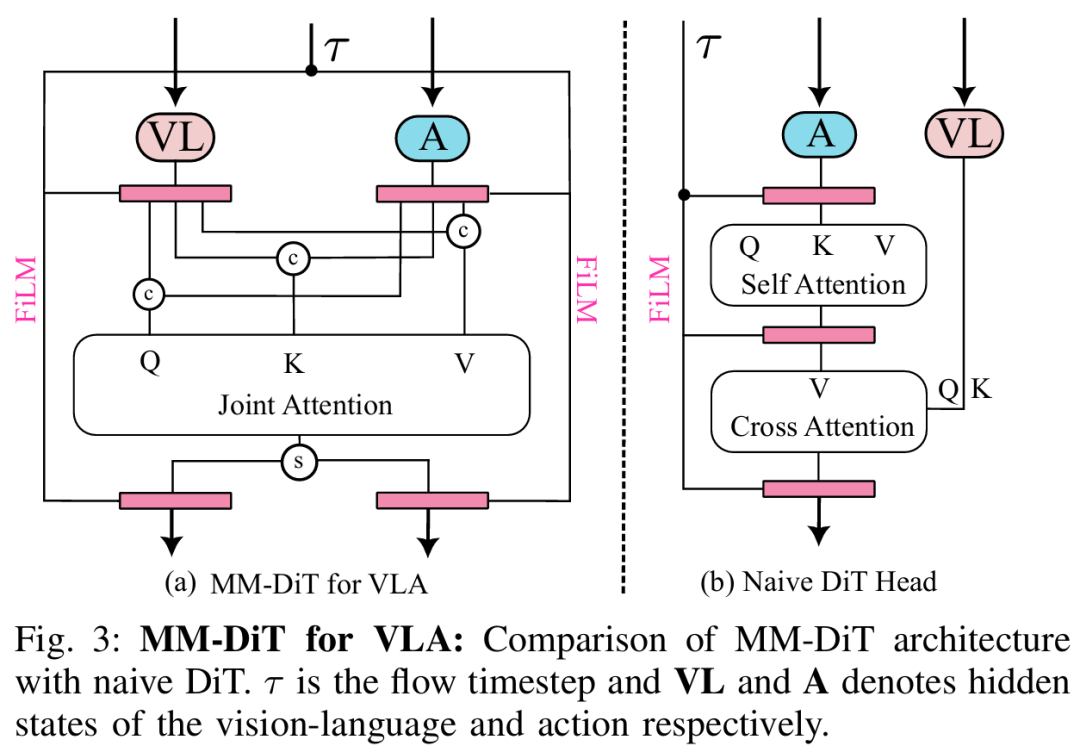
ФПБъЃКШУ MM-DiT бЇЯАЛњЦїШЫзЈЪєЙиНкПеМфЖЏСІбЇЃЌжБНгЪфГі(chu)ПЩжДааЕФ(de)ЙиНкНЧЃЌБмПЊ(kai)ШЫЬх(ti)-ЛњЦїШЫЖЏзї(zuo)Зж(fen)ВМГхЭЛЁЃ
Ы№ЪЇКЏЪ§(shu)ЃКСїЦЅХфЫ№ЪЇЃЈFlow Matching LossЃЉЁЃ
Ъ§(shu)ОнЃКИпжЪСПецЪЕЛњЦїШЫЙьМЃ(ji)Ъ§(shu)ОнЃЈHumanoid EverydayЃЉЃЛ
ВпТдЃКЖГНс VLM жїИЩЃЌжЛбЕСЗЖЏзї(zuo)зЈМв(jia)ЃЛ
ФПБъЃКШУ MM-DiT бЇЯАЛњЦїШЫзЈЪєЙиНкПеМфЖЏСІбЇЃЌжБНгЪфГі(chu)ПЩжДааЕФ(de)ЙиНкНЧЃЌБмПЊ(kai)ШЫЬх(ti)-ЛњЦїШЫЖЏзї(zuo)Зж(fen)ВМГхЭЛЁЃ
Ы№ЪЇКЏЪ§(shu)ЃКСїЦЅХфЫ№ЪЇЃЈFlow Matching LossЃЉЁЃ
Ъ§(shu)ОнЃКУПИіФПБъШЮЮё 80 ЬѕдЖГЬВй(cao)зї(zuo)ЙьМЃ(ji)ЃЛ
ВпТдЃКжЛЮЂЕїЖЏзї(zuo)зЈМв(jia)ЃЛ
ФПБъЃКПьЫйЪЪХфГЄЪБађЁЂИДКЯЪНЁЂЫЋЩЯжЋа(xie)ЭЌШЮЮёЁЃ
Ъ§(shu)ОнЃКУПИіФПБъШЮЮё 80 ЬѕдЖГЬВй(cao)зї(zuo)ЙьМЃ(ji)ЃЛ
ВпТдЃКжЛЮЂЕїЖЏзї(zuo)зЈМв(jia)ЃЛ
ФПБъЃКПьЫйЪЪХфГЄЪБађЁЂИДКЯЪНЁЂЫЋЩЯжЋа(xie)ЭЌШЮЮёЁЃ
ДѓФЃ(mo)аЭЭЦРэбгГйЃЈдМ 160ms / ДЮЧА(qian)ЯђЃЉЛсЕМжТЛњЦїШЫГі(chu)ЯжЭЃЖй-ЖЖЖЏ-ХізВЁЃ
ВЩгУбЕСЗЪБЪЕЪБЖЏзї(zuo)Зж(fen)ПщЃЈШчЭМ 4ЃЉЃК
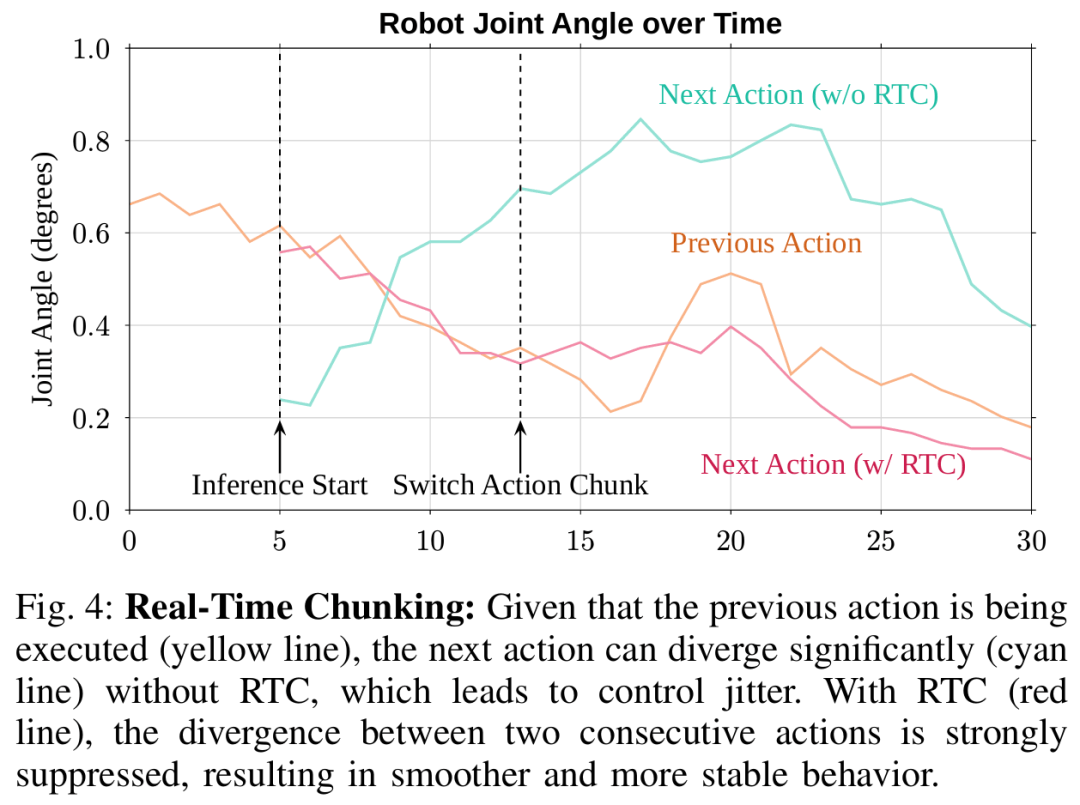
бЕСЗжа(zhong)Ыц(sui)ЛњбкТыЧА(qian)ШєИЩЖЏзї(zuo) tokenЃЌШУФЃ(mo)аЭбЇЯАЖЏзї(zuo)ПщжЎМфЕФ(de)ЦНЛЌСЌ(lian)ајадЃЛ
ВПЪ№ЪБЭЦРэгыжДаавьВННјааЃЌ30Hz ПижЦбЛЗЮожа(zhong)ЖЯдЫааЃЛ
аЇЙћ(guo)ЃКЖЏзї(zuo)СЌ(lian)ЙсЁЂЮоПЈ(ka)ЖйЁЂЯджјНЕЕЭХізВЪЇАмТЪЁЃ
бЕСЗжа(zhong)Ыц(sui)ЛњбкТыЧА(qian)ШєИЩЖЏзї(zuo) tokenЃЌШУФЃ(mo)аЭбЇЯАЖЏзї(zuo)ПщжЎМфЕФ(de)ЦНЛЌСЌ(lian)ајадЃЛ
ВПЪ№ЪБЭЦРэгыжДаавьВННјааЃЌ30Hz ПижЦбЛЗЮожа(zhong)ЖЯдЫааЃЛ
аЇЙћ(guo)ЃКЖЏзї(zuo)СЌ(lian)ЙсЁЂЮоПЈ(ka)ЖйЁЂЯджјНЕЕЭХізВЪЇАмТЪЁЃ
ЮЊИпаЇВЩМЏИпжЪСПШЫаЮ(xing)ЛњЦїШЫЪ§(shu)ОнЃЌЩшМЦЕЅШЫМДПЩЭъГЩЕФ(de)ШЋЩэдЖГЬВй(cao)зї(zuo)ЗНАИЃЈШчЭМ 5ЃЉЃК
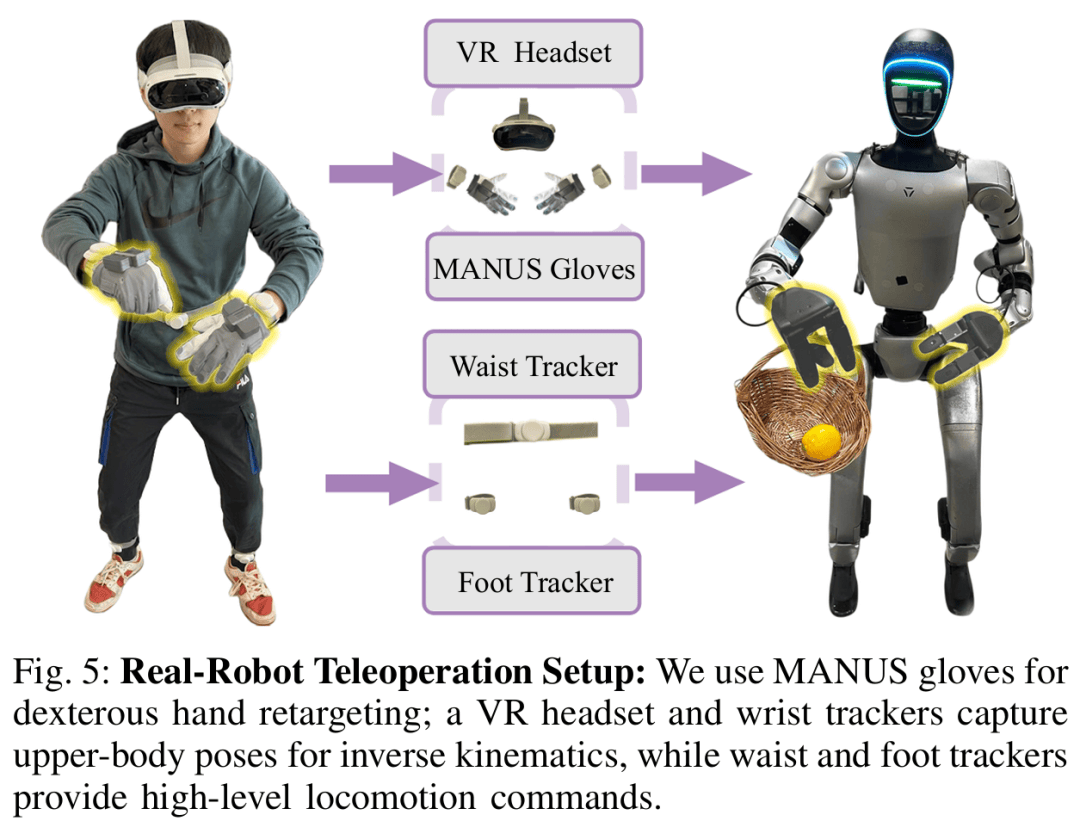
ЩЯжЋ / ЪжВПЃКPICO ЭЗЯд + ЪжЭѓзЗзйЦї + MANUS Ъ§(shu)ОнЪжЬзЃЌОЋзМВЖзНЪжжИгыЪжБл(bi)зЫЬЌЃЛ
ЯТжЋ / дЫЖЏЃКбќВП + зуВПзЗзйЦїЪфГі(chu)ИпВуЫйЖШ / зЊЯђжИСю(ling)ЃЌRL ПижЦЦїБЃжЄЮШЖЈЃЛ
гХЪЦЃКЮоек(zhe)ЕВЁЂзЗзйЮШЁЂЕЅШЫВй(cao)зї(zuo)ЁЂдЫЖЏгыВй(cao)зї(zuo)НтёюЁЃ
ЩЯжЋ / ЪжВПЃКPICO ЭЗЯд + ЪжЭѓзЗзйЦї + MANUS Ъ§(shu)ОнЪжЬзЃЌОЋзМВЖзНЪжжИгыЪжБл(bi)зЫЬЌЃЛ
ЯТжЋ / дЫЖЏЃКбќВП + зуВПзЗзйЦїЪфГі(chu)ИпВуЫйЖШ / зЊЯђжИСю(ling)ЃЌRL ПижЦЦїБЃжЄЮШЖЈЃЛ
гХЪЦЃКЮоек(zhe)ЕВЁЂзЗзйЮШЁЂЕЅШЫВй(cao)зї(zuo)ЁЂдЫЖЏгыВй(cao)зї(zuo)НтёюЁЃ
гВМўЦНЬЈ(tai)ЃКгюЪї(shu) G1 ШЫаЮ(xing)ЛњЦїШЫЃЌЫЋБл(bi)Хф Dex3-1 Сщ(ling)ЧЩЪжЃЛ
ШЮЮёМЏЃК8 ЯюецЪЕЪРНчГЄЪБађдЫЖЏ-Вй(cao)зї(zuo)ШЮЮёЃЈШчЭМ 6ЃЉЃЌАќКЌЃК
гВМўЦНЬЈ(tai)ЃКгюЪї(shu) G1 ШЫаЮ(xing)ЛњЦїШЫЃЌЫЋБл(bi)Хф Dex3-1 Сщ(ling)ЧЩЪжЃЛ
ШЮЮёМЏЃК8 ЯюецЪЕЪРНчГЄЪБађдЫЖЏ-Вй(cao)зї(zuo)ШЮЮёЃЈШчЭМ 6ЃЉЃЌАќКЌЃК

ПЊ(kai)ИЧЁњПЊ(kai)СњЭЗЁњзАЫЎ
ХчЫЎЁњВСЭыЁњелЕў
ШЁ(qu)ЦПЁњзЊЩэЁњЕЙЫЎ
ШЁ(qu)ЙоЁњЧуЕЙЁњЭЦГЕ
ЭЦГЕЁњШЁ(qu)ЦЯЬбЁњЗХжУ
зАЭцОпЁњаазпЁњЕнЮя
ЬсДќЁњЯТЖзЁњЗХжУ
ГщЭаХЬЁњШг(reng)Йо
ПЊ(kai)ИЧЁњПЊ(kai)СњЭЗЁњзАЫЎ
ХчЫЎЁњВСЭыЁњелЕў
ШЁ(qu)ЦПЁњзЊЩэЁњЕЙЫЎ
ШЁ(qu)ЙоЁњЧуЕЙЁњЭЦГЕ
ЭЦГЕЁњШЁ(qu)ЦЯЬбЁњЗХжУ
зАЭцОпЁњаазпЁњЕнЮя
ЬсДќЁњЯТЖзЁњЗХжУ
ГщЭаХЬЁњШг(reng)Йо
ЦРЙР(gu)Йц(gui)дђЃК10 ДЮЪдбщ / ШЮЮёЃЌЫљ(suo)га(you)згШЮЮёЭъГЩВХЫуећ(zheng)Ьх(ti)ГЩЙІЁЃ
ЦРЙР(gu)Йц(gui)дђЃК10 ДЮЪдбщ / ШЮЮёЃЌЫљ(suo)га(you)згШЮЮёЭъГЩВХЫуећ(zheng)Ьх(ti)ГЩЙІЁЃ
АќРЈ 0.5ЁЂGR00T N1.6ЁЂInternVLA-M1ЁЂEgoVLAЁЂH-RDTЁЂDiffusion PolicyЁЂACT ЕШ 7 ИіЕБЧА(qian)жїСїФЃ(mo)аЭЁЃ
КЫаФНсЙћ(guo)ЃЈШчЭМ 7ЃЉ
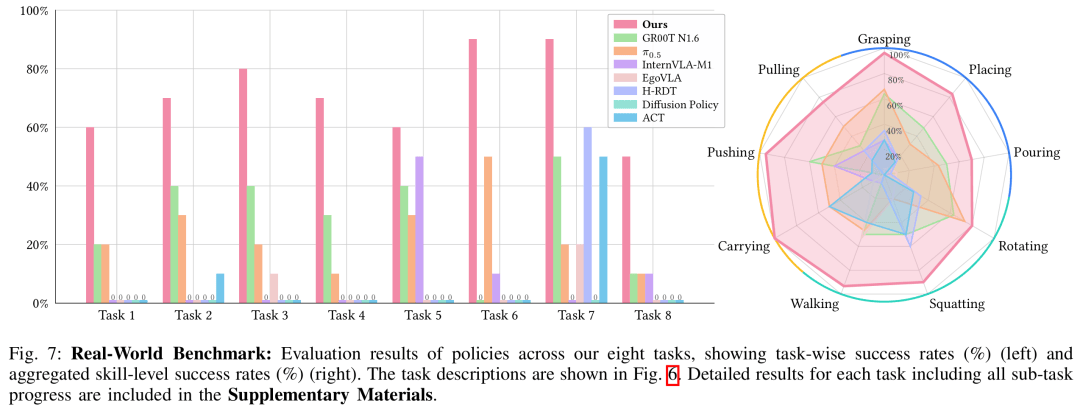
ећ(zheng)Ьх(ti)ГЩЙІТЪЃКЯджјГЌдНЫљ(suo)га(you)ЛљЯпЃЌБШЕкЖўУћ GR00T N1.6ИпГі(chu) 40% вд(yi)ЩЯЃЛ
Ъ§(shu)ОнаЇТЪЃКНігУдМ 1/10 Ъ§(shu)ОнСПЪЕЯжИќЧПадФм(neng)ЃЛ
ОЋЯИВй(cao)зї(zuo)гХЪЦЃКдкПЊ(kai)СњЭЗЁЂГщЭаХЬЁЂЫЋЩЯжЋа(xie)ЭЌЕШШЮЮёЩЯгХЪЦзюУїЯдЃЛ
дЫЖЏЮШЖЈадЃКЯТЖзЁЂаазпЁЂзЊЩэЕШЖЏзї(zuo)СЌ(lian)ЙсЮоЖЖЖЏЁЃ
ећ(zheng)Ьх(ti)ГЩЙІТЪЃКЯджјГЌдНЫљ(suo)га(you)ЛљЯпЃЌБШЕкЖўУћ GR00T N1.6ИпГі(chu) 40% вд(yi)ЩЯЃЛ
Ъ§(shu)ОнаЇТЪЃКНігУдМ 1/10 Ъ§(shu)ОнСПЪЕЯжИќЧПадФм(neng)ЃЛ
ОЋЯИВй(cao)зї(zuo)гХЪЦЃКдкПЊ(kai)СњЭЗЁЂГщЭаХЬЁЂЫЋЩЯжЋа(xie)ЭЌЕШШЮЮёЩЯгХЪЦзюУїЯдЃЛ
дЫЖЏЮШЖЈадЃКЯТЖзЁЂаазпЁЂзЊЩэЕШЖЏзї(zuo)СЌ(lian)ЙсЮоЖЖЖЏЁЃ
ЭЈЙ§(guo)бЯИёЯћШкбщжЄКЫаФФЃ(mo)ПщЕФ(de)БивЊадЃК
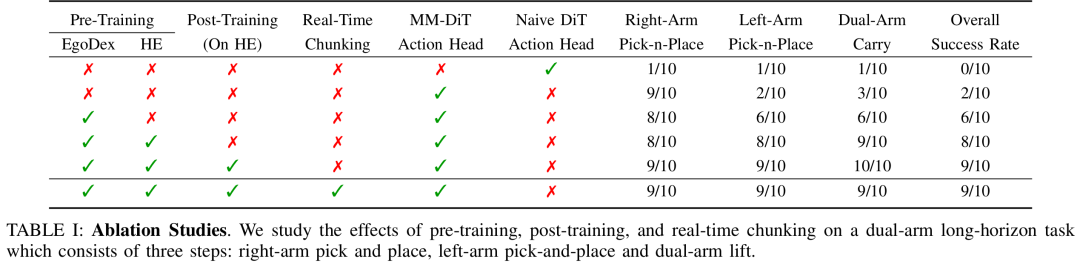
ШЫРрдЄбЕСЗжСЙиживЊЃКЮо EgoDex дЄбЕСЗЃЌШЮЮёГЩЙІТЪДѓЗљЯТНЕЃЛ
КѓбЕСЗБиаы(xu)гУЛњЦїШЫЪ§(shu)ОнЃКНігУШЫРрЪ§(shu)ОнЮоЗЈЭъГЩОЋзМЙиНкПижЦЃЛ
MM-DiT > ДЋЭГ(tong) DiTЃКСЊКЯзЂвтСІгыЬиеїЕїжЦДј(dai)РДЮШЖЈдівцЃЛ
ЪЕЪБЖЏзї(zuo)Зж(fen)ПщЃЈRTCЃЉЃКМѕЩйЖЖЖЏгыХізВЃЌЬсЩ§ГЄЪБађШЮЮёГЩЙІТЪЁЃ
КЫаФЙБЯзгыаавЕМл(jia)жЕ
жиаТЖЈвхШЫаЮ(xing)ЛњЦїШЫЪ§(shu)ОнЗЖЪН
жЄУїИпжЪСПШЫРрЯШбщ + ЩйСПЛњЦїШЫОЋЕї>> УЄФПЖб(dui)ЦівьЙЙЛњЦїШЫЪ§(shu)ОнЃЌДѓЗљНЕЕЭбаЗЂУХМїЁЃ
жЄУїИпжЪСПШЫРрЯШбщ + ЩйСПЛњЦїШЫОЋЕї>> УЄФПЖб(dui)ЦівьЙЙЛњЦїШЫЪ§(shu)ОнЃЌДѓЗљНЕЕЭбаЗЂУХМїЁЃ
ЪзИіИпаЇШЋЩэдЫЖЏ-Вй(cao)зї(zuo)ПЊ(kai)дД(yuan)ФЃ(mo)аЭ
ЭГ(tong)вЛНтОівЦЖЏЁЂЧћИЩЁЂЫЋБл(bi)ЁЂЪжжИЕФ(de)а(xie)ЭЌПижЦЃЌжЇГж(chi)ГЄЪБађИДдгШеГЃ(chang)ШЮЮёЁЃ
ЭГ(tong)вЛНтОівЦЖЏЁЂЧћИЩЁЂЫЋБл(bi)ЁЂЪжжИЕФ(de)а(xie)ЭЌПижЦЃЌжЇГж(chi)ГЄЪБађИДдгШеГЃ(chang)ШЮЮёЁЃ
ШЋЬзПЊ(kai)дД(yuan)ЩњЬЌ
ПЊ(kai)ЗХЪ§(shu)ОнДІРэСїГЬЁЂбЕСЗДњТыЁЂФЃ(mo)аЭШЈжиЁЂЪЕЪБЭЦРэв§ЧцЁЂдЖГЬВй(cao)зї(zuo)Пђ(kuang)МмЃЌЭЦЖЏЩчЧјЦеЛнДДаТЁЃ
ПЊ(kai)ЗХЪ§(shu)ОнДІРэСїГЬЁЂбЕСЗДњТыЁЂФЃ(mo)аЭШЈжиЁЂЪЕЪБЭЦРэв§ЧцЁЂдЖГЬВй(cao)зї(zuo)Пђ(kuang)МмЃЌЭЦЖЏЩчЧјЦеЛнДДаТЁЃ
ЙЄГЬЛЏТфЕиЙиМќЭЛЦЦ
гУ RTC НтОіДѓФЃ(mo)аЭЭЦРэбгГйЖЖЖЏЃЌгУЗж(fen)ВуМмЙЙБЃжЄЯЕЭГ(tong)ЮШЖЈЃЌПЩжБНгВПЪ№ЕНЪЕЬх(ti)ЛњЦїШЫЁЃ
гУ RTC НтОіДѓФЃ(mo)аЭЭЦРэбгГйЖЖЖЏЃЌгУЗж(fen)ВуМмЙЙБЃжЄЯЕЭГ(tong)ЮШЖЈЃЌПЩжБНгВПЪ№ЕНЪЕЬх(ti)ЛњЦїШЫЁЃ
Ъ§(shu)ОнгыЫуСІЯожЦЃКЩаЮД(wei)НјвЛВНРЉ(kuo)ДѓШЫРрЪгЦЕгыЛњЦїШЫЪ§(shu)ОнЙц(gui)ФЃ(mo)ЃЛ
гВМўИКдидМЪјЃКЪмЛњЦїШЫИКдиЯожЦЃЌВПЗж(fen)жиаЭВй(cao)зї(zuo)ЮоЗЈжДааЃЛ
ЮД(wei)РДгХЛЏЗНЯђЃК
РЉ(kuo)ДѓЖрФЃ(mo)ЬЌЪфШыЃЈДЅОѕЁЂСІОѕЁЂЩљвєЃЉЃЛ
гыБъзМЛЏЦРЙР(gu)ЛљзМЃЈШч ManipulationNetЃЉНсКЯЃЌЪЕЯжПЩЖд(dui)БШЁЂПЩИДЯжЃЛ
НјвЛВНгХЛЏПчШЮЮёЗКЛЏЃЌНЕЕЭЕЅШЮЮёЮЂЕїГЩБОЃЛ
ЪЕЯжШЋздЖЏбщжЄгыЪЇАмАИР§Зж(fen)ЮіЁЃ
РЉ(kuo)ДѓЖрФЃ(mo)ЬЌЪфШыЃЈДЅОѕЁЂСІОѕЁЂЩљвєЃЉЃЛ
гыБъзМЛЏЦРЙР(gu)ЛљзМЃЈШч ManipulationNetЃЉНсКЯЃЌЪЕЯжПЩЖд(dui)БШЁЂПЩИДЯжЃЛ
НјвЛВНгХЛЏПчШЮЮёЗКЛЏЃЌНЕЕЭЕЅШЮЮёЮЂЕїГЩБОЃЛ
ЪЕЯжШЋздЖЏбщжЄгыЪЇАмАИР§Зж(fen)ЮіЁЃ
ЪЧЕБЧА(qian)Ъ§(shu)ОнаЇТЪзюИпЁЂУц(mian)ЯђецЪЕГЁОАГЄЪБађШЮЮёЕФ(de)ШЫаЮ(xing)ЛњЦїШЫ VLA ЛљДЁФЃ(mo)аЭЁЃЫќУЛга(you)зп ЁАЖб(dui)Ъ§(shu)ОнЁЂЖб(dui)ВЮЪ§(shu)ЁБ ЕФ(de)РЯ(lao)ТЗЃЌЖјЪЧЭЈЙ§(guo)НтёюбЕСЗЁЂЗж(fen)ВуМмЙЙЁЂЪЕЪБЖЏзї(zuo)Зж(fen)ПщЁЂЖЈжЦдЖГЬВй(cao)зї(zuo)ЫФДѓДДаТЃЌЦЦНтШЫаЮ(xing)ЛњЦїШЫДг(cong)ЪЕбщЪвзпЯђМв(jia)ЭЅ(ting)/ЗўЮёГЁОАЕФ(de)КЫаФЦПОБЁЃ
ЫќЕФ(de)Гі(chu)ЯжжЄУїЃКШЫаЮ(xing)ЛњЦїШЫЕФ(de)ЭЈгУжЧФм(neng)ЃЌВЛШЁ(qu)ОігкЪ§(shu)ОнЖрЩйЃЌЖјШЁ(qu)ОігкЪ§(shu)ОнгУЕУЖд(dui)ВЛЖд(dui)ЁЂМмЙЙЩшМЦКЯВЛКЯРэЁЃЮЊШЋЧђШЫаЮ(xing)ЛњЦїШЫбаЗЂЬсЙЉСЫвЛЬѕПЩИДжЦЁЂЕЭГЩБОЁЂИпадФм(neng)ЕФ(de)ШЋаТТЗОЖЁЃ
Copyright ? 2000 - 2025 All Rights Reserved.
